Last year, I transitioned to doing data engineering and data warehousing work. It’s been an interesting journey so far—I’m still very much learning—but I thought I would make a post about the insights I’ve had into the nature of this work and the surprises I’ve encountered.
First off, anyone interested in this topic should read Maxime Beauchemin’s article, “The Rise of the Data Engineer”. It’s a great overview of this role’s emergence within the growing field of data science. He writes: “Like data scientists, data engineers write code. They’re highly analytical, and are interested in data visualization. Unlike data scientists — and inspired by our more mature parent, software engineering — data engineers build tools, infrastructure, frameworks, and services. In fact, it’s arguable that data engineering is much closer to software engineering than it is to a data science.”
I can’t speak to data science just yet, as that is relatively new to me as well. But I’ve been doing software engineering for a while now, so my reflections here come from that perspective.
Thinking in Sets
When I started, I thought, how hard can this be? Isn’t it just writing SQL? I’ve done that. Piece of cake, right? Yes and no.
Though I’ve worked a lot with transactional databases, writing complex queries for ETL and reporting purposes requires a very different mindset. Especially when you are writing stored procedures composed of statements that join several tables, pivot the result, transform and filter rows using ranking window functions, and then union a bunch of tables together. It takes some time to train your brain to map higher-level operations to the crazy-looking SELECT statements or lengthy groups of common table expressions that perform them. Much of this is due to SQL being such an odd beast compared to the mainstream object-oriented languages of the day (more on that below).
Relational databases are all about sets, so you have to resist your imperative impulses. For example, instead of doing things iteratively in a loop containing IF statements inside it, you can probably express the same thing using a cartesian product and WHERE clauses. It’s usually faster, the code is more compact, and it takes advantage of the set-oriented nature of the language. Joe Celko’s Thinking in Sets is a good book that’s helped me adjust to, well, thinking in sets. I highly recommend it.
Programming Skills
So after these initial experiences, my thinking changed to: “okay, this stuff really is a different animal than software development.” Again, yes and no.
I’ve noticed that functional programming and “big data” trends have had a lot of influence on data engineering. Traditional practices from data warehousing, shaped in large part by Kimball, are still relevant, but they’ve also been changing in response to these new developments. Designing ETL pipelines with immutability in mind, a core concept from FP, makes them much easier to understand and troubleshoot. The irony here is that while declarative languages have been getting a lot of attention in recent years, SQL often goes unrecognized as a member of this category, even as it’s been around forever. (Because let’s face it, SQL just isn’t sexy.)
The data warehouse I work on is a custom-built system of stored procedures in SQL Server. This gives us tremendous control and flexibility that we wouldn’t have with an off-the-shelf warehousing or ETL product. It also means I write a lot of scripts in PowerShell and R to do preprocessing, loads, builds, updates, etc. While those languages are new to me, having a background in coding has helped tremendously with hitting the ground running. Beauchemin ntoes the general move away from GUI-based products towards code, a trend which I wholeheartedly support: “There’s a multitude of reasons why complex pieces of software are not developed using drag and drop tools: it’s that ultimately code is the best abstraction there is for software.”
Along those lines, designing tables and relationships is basically an exercise in abstraction, sharing a lot of similarities with designing data structures and object classes. However, a major annoyance I’ve found with SQL databases is that I often find I can’t achieve the same degree of abstraction as with other languages and technologies. You can’t group together fields from a table and work with that group repeatedly. There’s no table inheritance and table “typing”, in a way that allows you to use only certain types of tables (those implementing a certain set of columns, for example) in a query that you want to restrict in this way. The limits on abstraction also limit code reuse.
I suspect these hindrances are a major reason for the move away from SQL towards other languages to do data processing.
A Priori Guarantees and Empirical Validation
The biggest difference is actually a subtle one that’s taken me a long time to identify and name.
Compiled languages like Java give you a lot of a priori guarantees. This lets you create very modular code and also have confidence that the pieces work together in extremely well-defined ways.
When working with data pipelines, the pieces are much more loosely coupled. I find it more challenging to reason about the potential effects of changes you make at any given stage of a pipeline, especially when data flows out of one system into another. So I find myself doing a lot more validation at each stage to make up for this. I try to get unexpected consequences to raise errors instead of just “failing” silently (where “fail” here means that a JOIN or a WHERE clause that simply stops matching). This means a lot more manual work, unfortunately. I imagine people out there are thinking about how to effectively handle upstream changes in a sane way, but I’m not quite there yet.
Making Tools
In software development, I’ve always felt more comfortable doing back-end rather than front-end work. Data engineering fits into that mindset very well. At almost every job I’ve had, I jumped at the chance to create tools and utilities. This has always been an auxiliary thing, but I’m finding it to be more front and center in data engineering, which is really enjoyable and gratifying to me.
Some people hate writing the “glue” pieces to get systems to work, but I love it. They’re often chances to think about architecture, modularity, interfaces, and optimization. There’s something very satisfying about that sort of thinking. It feels more like computing, in a world where that term has almost completely lost meaning.
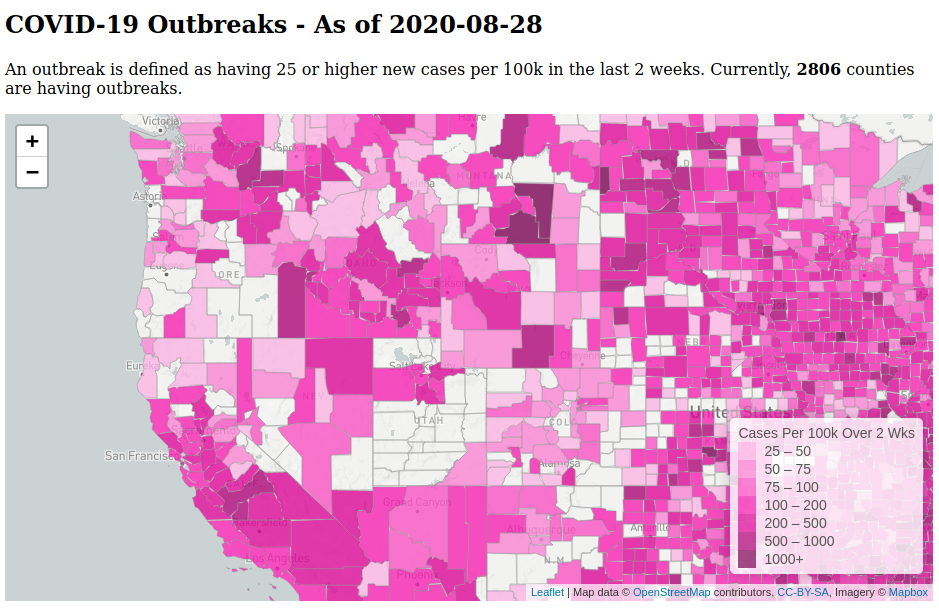 Life under this pandemic has been hard. Oddly, one of the things that’s helped me deal is to play around with the coronavirus data. The numbers in the U.S. are horrifying, of course, but they’ve also been soothing at a technical level, maybe because working with the data is somewhat different from the work I do for my job. It’s also been neat to do hands-on validation of reporting in the media and various claims made about trends. I’ve been showing my results to friends who seem to find them insightful.
Life under this pandemic has been hard. Oddly, one of the things that’s helped me deal is to play around with the coronavirus data. The numbers in the U.S. are horrifying, of course, but they’ve also been soothing at a technical level, maybe because working with the data is somewhat different from the work I do for my job. It’s also been neat to do hands-on validation of reporting in the media and various claims made about trends. I’ve been showing my results to friends who seem to find them insightful.